很多建站系统,建站后都有网站的根目录,默认带有robots.txt协议文件。在如今竞争日益激烈的网站优化中,原本没有优化因素设置的robots.txt文件也得到最大程度的利用,其编写也是为了应对突发事件而掌握的。1:robots . txt[...]
很多建站系统,建站后都有网站的根目录,默认带有robots.txt协议文件。在如今竞争日益激烈的网站优化中,原本没有优化因素设置的robots.txt文件也得到最大程度的利用,其编写也是为了应对突发事件而掌握的。
I:robots . txt协议文件有什么用?
当搜索引擎访问一个网站时,它访问的第一个文件是robots.txt。她告诉搜索引擎蜘蛛哪些网页可以爬行,哪些网页禁止爬行。表面上看,这个功能作用有限。从搜索引擎优化的角度来看,屏蔽页面可以实现集中权重的功能,这也是优化者最看重的地方。
以一个seo站点为例,它的robots.txt文件如图:
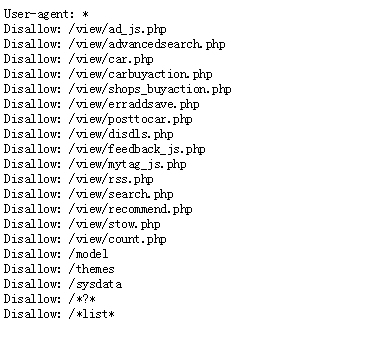
二:在网站上设置robots.txt的几个理由。
1.设置访问权限以保护网站安全。
2.禁止搜索引擎抓取无效页面,将权重集中在主页面。
【/s2/】三:如何用标准写法写协议?
有几个概念需要掌握。
用户代理就是定义哪个搜索引擎,比如用户代理:百度蜘蛛,定义百度蜘蛛。
不允许意味着禁止访问。
允许表示运行访问。
通过以上三个命令,可以结合多种编写方法,允许哪个搜索引擎访问,禁止哪个页面访问。
IV:robots . txt文件在哪里?
这个文件需要放在网站的根目录下,字母大小有限。文件名必须是小写字母。所有命令的第一个字母应该大写,其余的应该小写。而且命令后面应该有英文字符空。
V:什么时候需要使用这个协议?[/s2/]
1.无用页面,很多网站都有联系我们,用户协议等页面,相比搜索引擎优化作用不大。此时,有必要使用“不允许”命令来禁止搜索引擎对这些页面进行爬网。
2.动态页面,企业型网站屏蔽动态页面,有利于网站安全。而且多个网站访问同一个页面,会导致权重分散。因此,一般来说,动态页面被屏蔽,静态或伪静态页面被保留。
3.网站背景页,网站背景页也可以归为无用页,禁止无伤大雅的囊括一切利益。
来源:robots.txt协议

